Note: Most of the code snippets are images because that was the only way to preserve SQL syntax highlighting. For an interactive code example, check out this Kaggle notebook.
Motivation
The goal of FugueSQL is to provide an enhanced SQL interface (and experience) for data professionals to perform end-to-end data compute workflows in a SQL-like language. With FugueSQL, SQL users can perform full Extract, Transform, Load (ETL) workflows on DataFrames inside Python code and Jupyter notebooks. The SQL is parsed and mapped to the corresponding Pandas, Spark, or Dask code.
This empowers heavy SQL users to harness the power of Spark and Dask, while using their language of choice to express logic. Additionally, distributed compute keywords have been added such as PREPARTITIONandPERSIST, in order to extend the capabilities beyond standard SQL.
In this article we’ll go over the basic FugueSQL features, and how to use it on top of Spark or Dask by specifying the execution engine.
Enhancements Over ANSI SQL
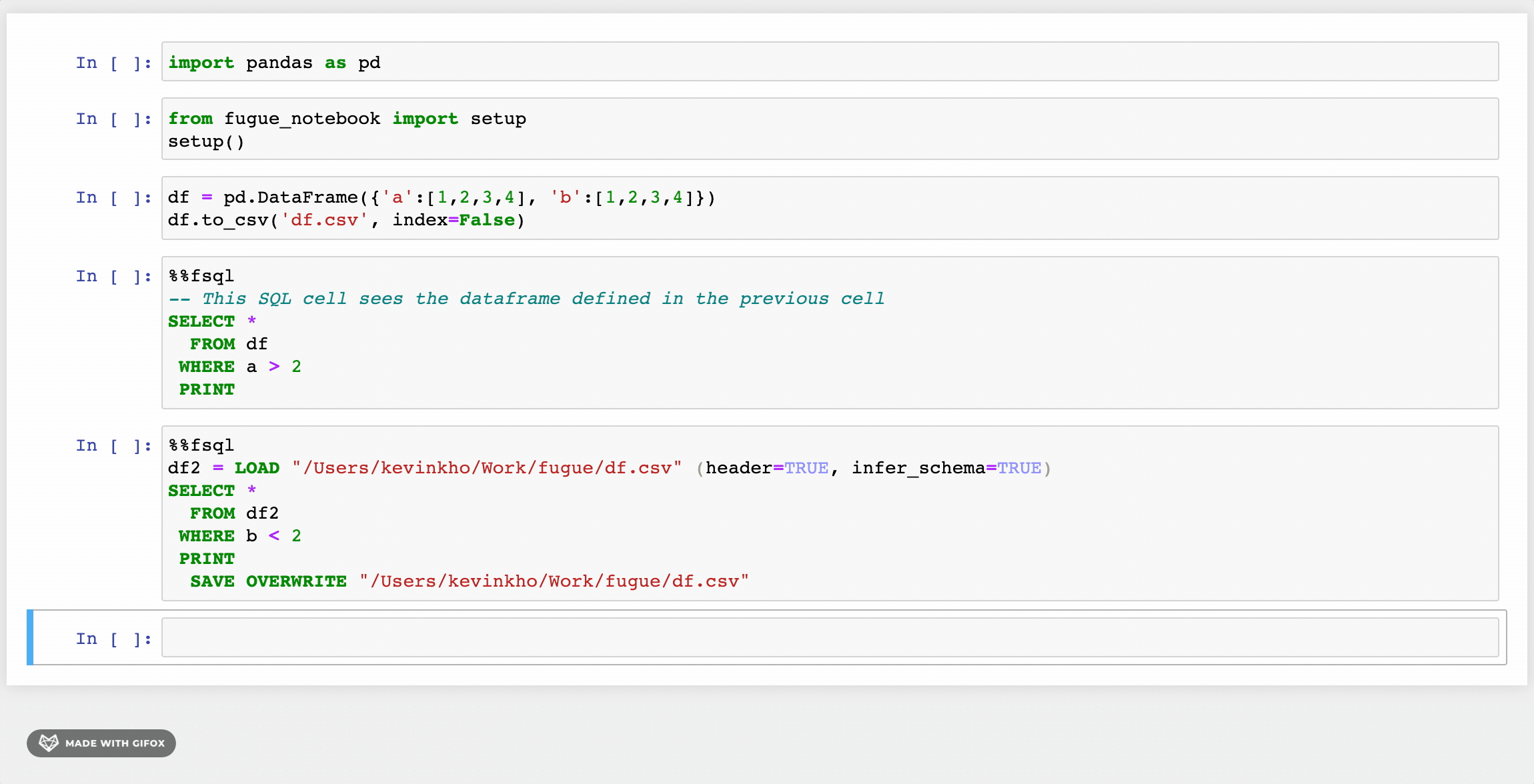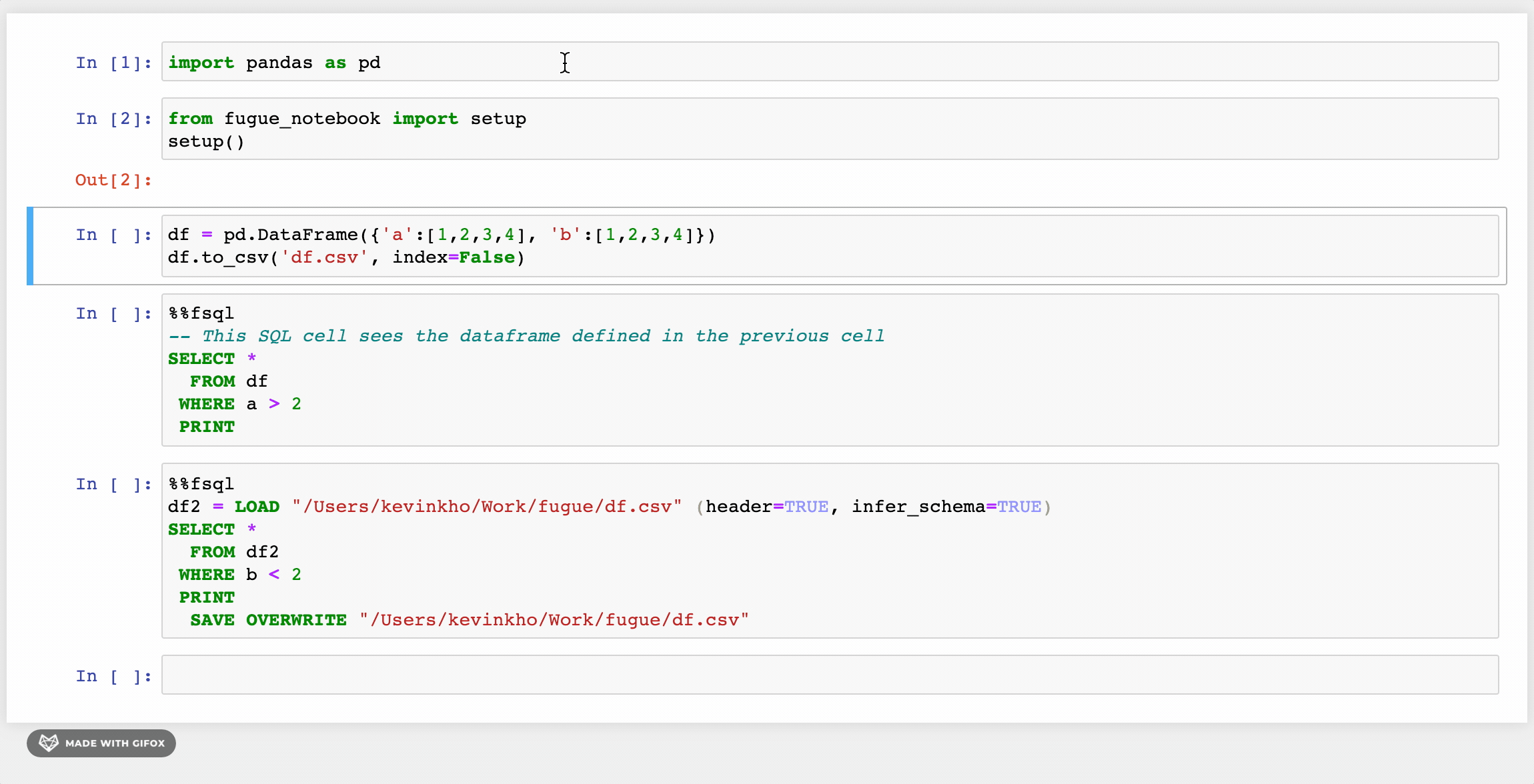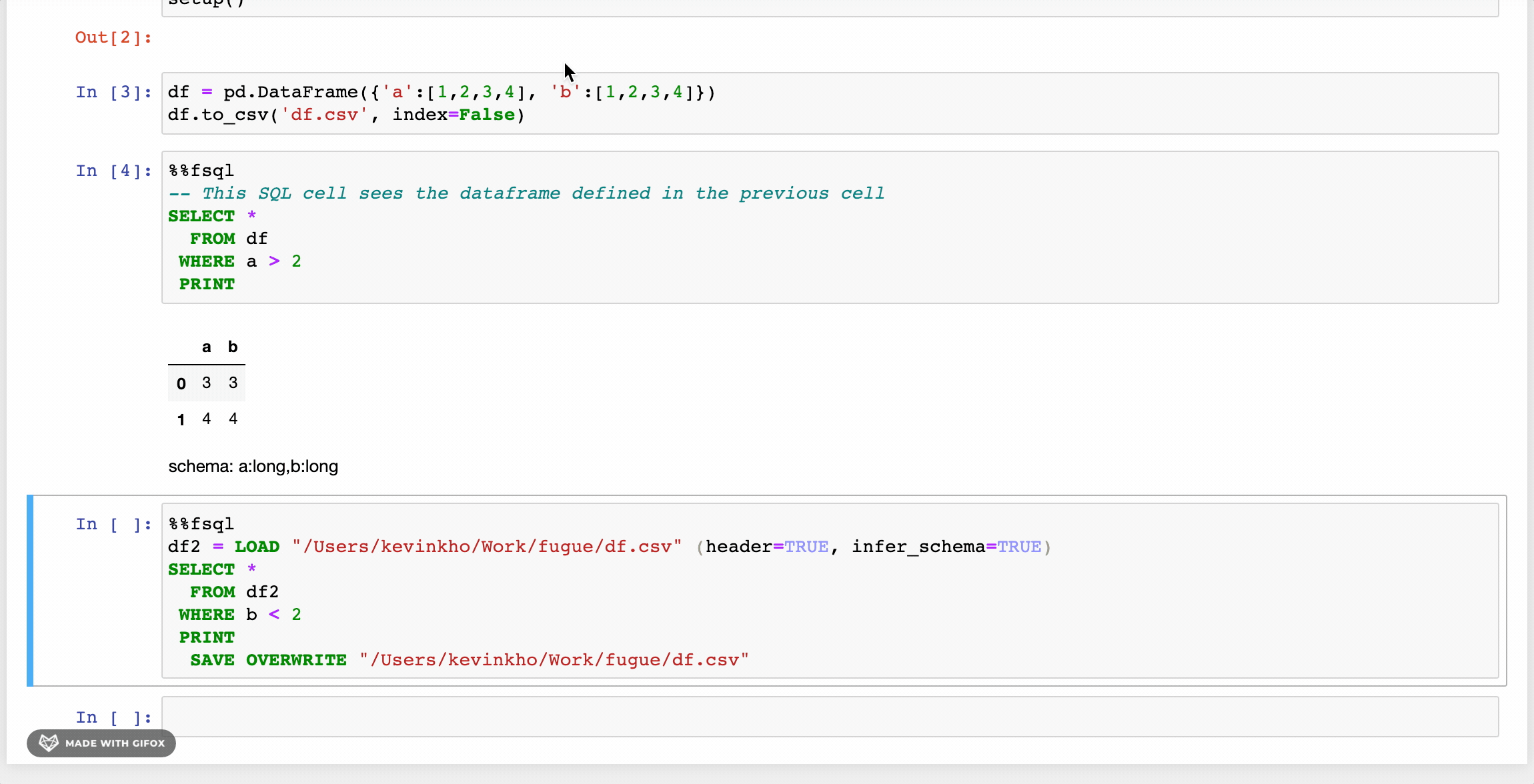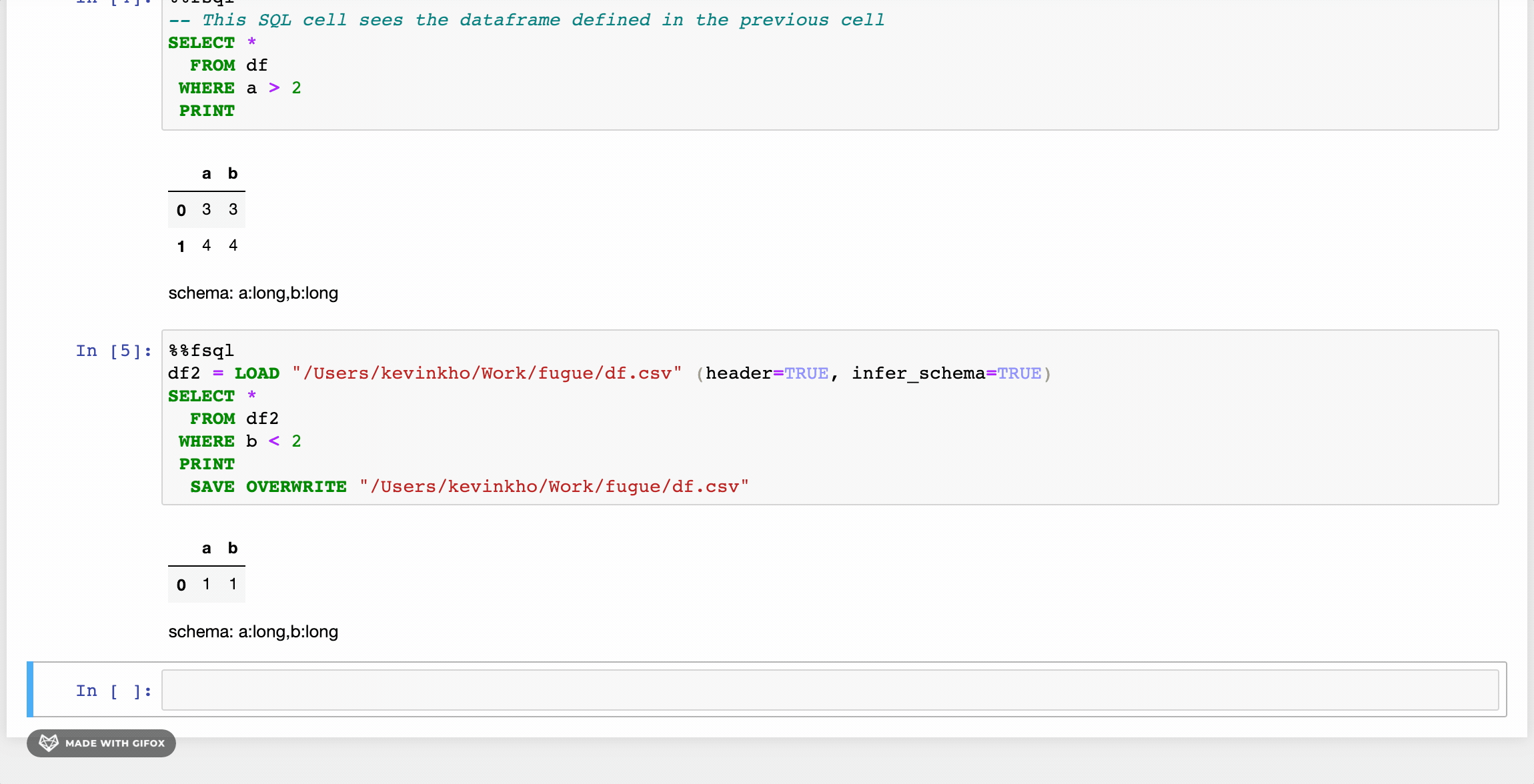
The first changes as seen in the GIF above are the LOADand SAVE keywords. Beyond these, there are some other enhancements that provide a friendlier syntax. Users can also use Python functions inside FugueSQL, creating a powerful combination.
FugueSQL users can have SQL cells in notebooks (more examples later) by using the %%fsqlcell magic. This also provides syntax highlighting in Jupyter notebooks. Although not demonstrated here, these SQL cells can be used in Python code with thefsql() function.
Variable Assignment
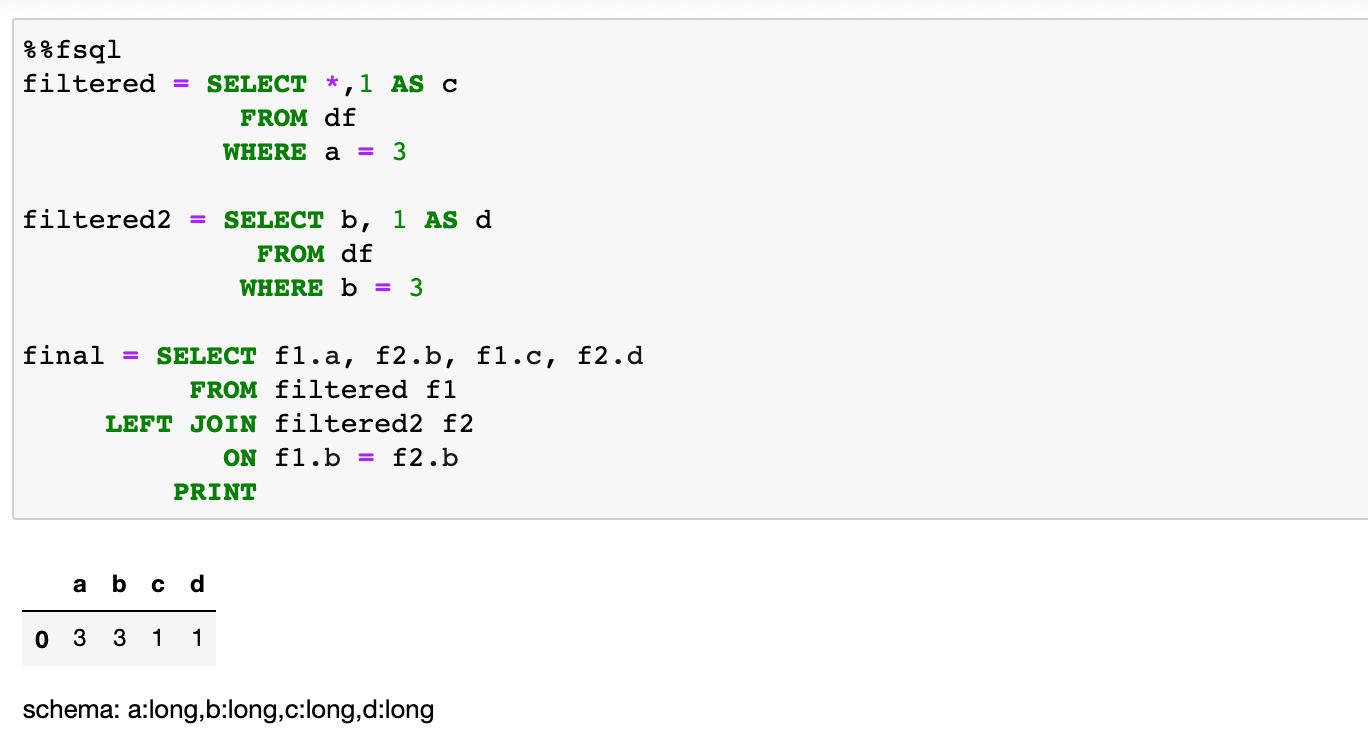
DataFrames can be assigned to variables. This is similar to SQL temp tables or Common Table Expressions (CTE). Although not shows in this tutorial, these DataFrames can also be brought out of the SQL cells and used in Python cells. The example below shows two new DataFrames that came from modifying df . dfwas created by using Pandas in a Python cell (this is the same df as the first image). The two new DataFrames are joined together to create a DataFrame namedfinal.
Jinja Templating
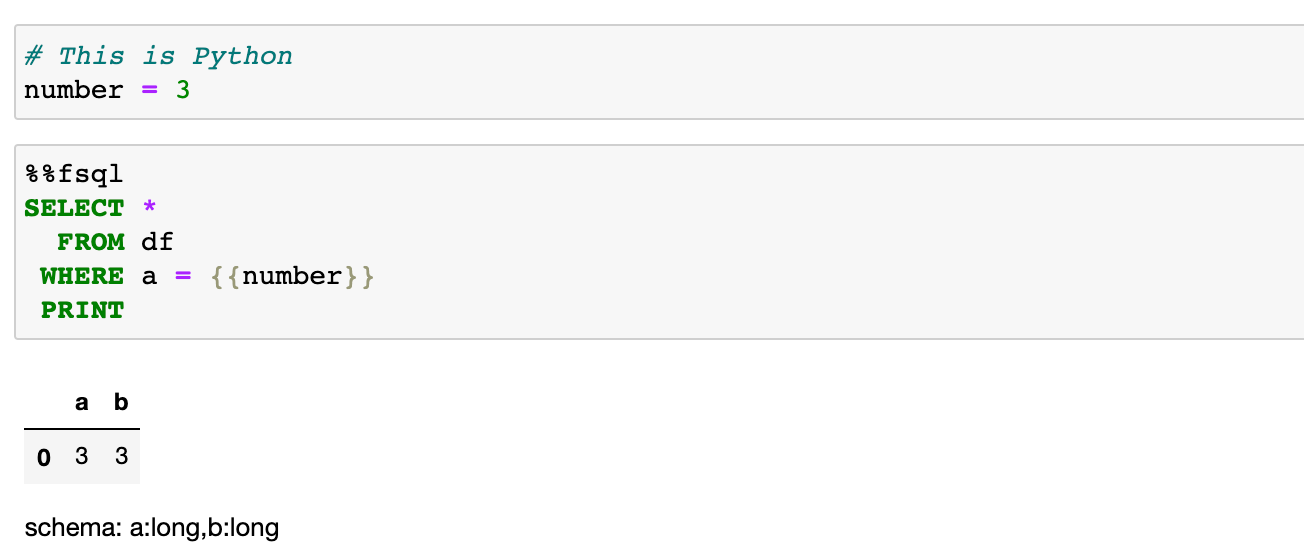
FugueSQL can interact with Python variables through Jinja templating. This allows Python logic to alter SQL queries similar to parameters in SQL.
Python Functions
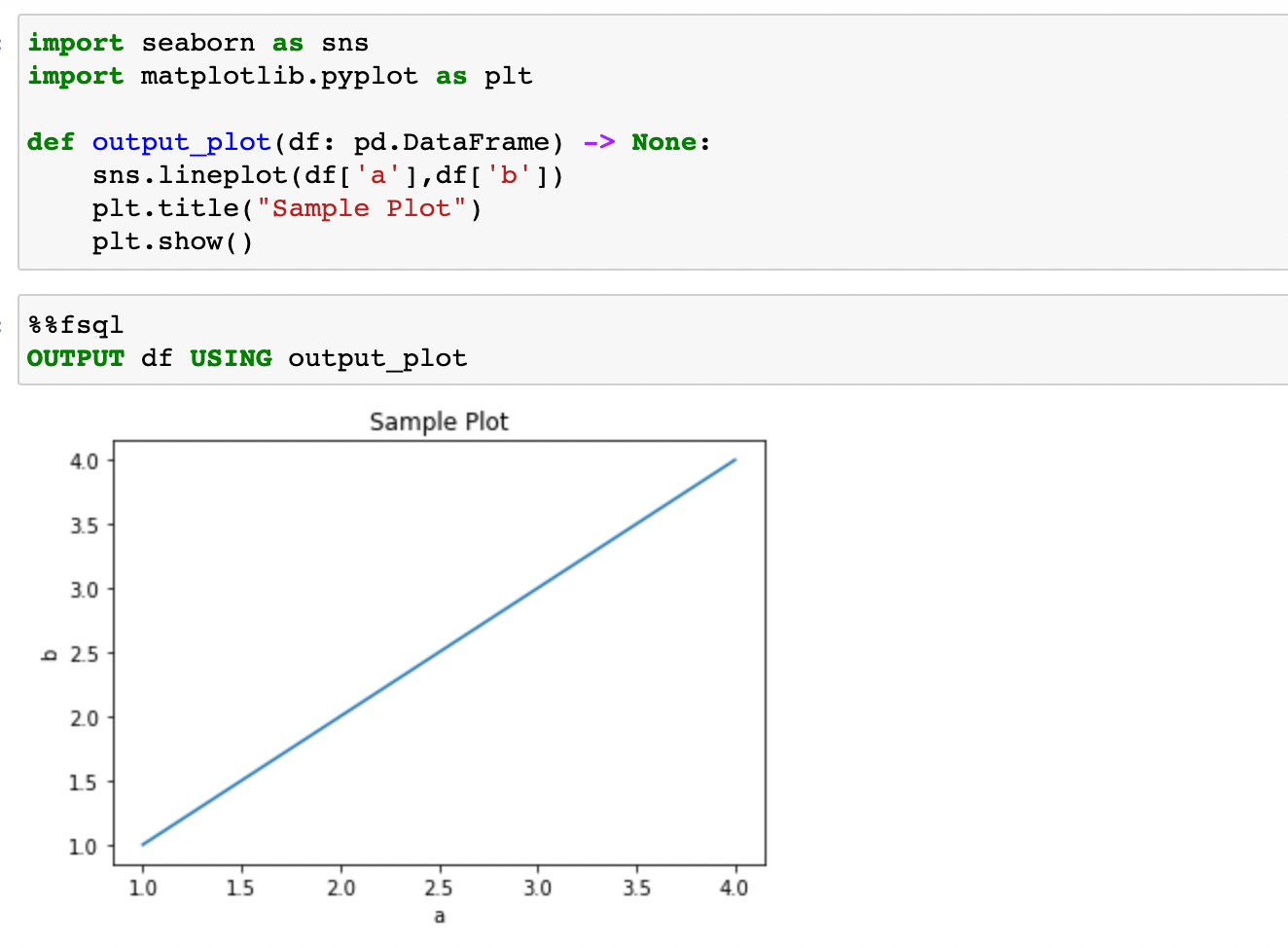
FugueSQL also supports using Python functions inside SQL code blocks. In the example below, we use seaborn to plot two columns of our DataFrame. We invoke the function using the OUTPUT keyword in SQL.
Comparison to ipython-sql

FugueSQL is meant to operate on data that is already loaded into memory (although there are ways to use FugueSQL to bring in data from storage). There is a project called ipython-sql that provides the %%sql cell magic command. This command is meant to use SQL to load data into the Python environment from a database.
FugueSQL’s guarantee is that the same SQL code will work on Pandas, Spark, and Dask without any code change. The focus of FugueSQL is in-memory computation, as opposed to loading data from a database.
Distributed Compute with Spark and Dask
As the volume of data we work with continues to increase, distributed compute engines such as Spark and Dask are becoming more widely adopted by data teams. FugueSQL allows users to use these more performant engines the same FugueSQL code.
In the code snippet below, we just changed the cell magic from %%fsql to %%fsql spark and now the SQL code will run on the Spark execution engine. Similarly, %%fsql dask will run the SQL code on the Dask execution engine.

One of the common operations that can benefit from moving to a distributed compute environment is getting the median of each group. In this example, we’ll show the PREPARTITIONkeyword and how to apply a function on each partition of data.
First, we define a Python function that takes in a DataFrame and outputs the user_id and the median measurement. This function is meant to operate on only one user_id at a time. Even if the function is defined in Pandas, it will work on Spark and Dask.
python1#schema: user_id:int, measurement:int
2
3def get_median(df:pd.DataFrame) -> pd.DataFrame:
4 return pd.DataFrame({'user_id': [df.iloc[0]['user_id']],
5 'median' : [df[['measurement']].median()]})
We can then use the PREPARTITION keyword to partition our data by the user_id and apply the get_median function.

In this example, we get the median measurement of each user. As the data size gets larger, more benefits will be seen from the parallelization. In an example notebook we have, the Pandas engine took around 520 seconds for this operation. Using the Spark engine (parallelized on 4 cores) took around 70 seconds for a dataset with 320 million rows.
The difference in execution time is expected. What FugueSQL allows SQL users to do is extend their workflows to Spark and Dask when the data becomes too big for Pandas to effectively handle.
Another common use-case is Dask handles memory spillover and writing data to the disk. This means users can process more data before hitting out-of-memory issues.
Conclusion and More Examples
In this article, we explored the basics features of FugueSQL that allow users to work on top of Pandas, Spark, and Dask DataFrames through SQL cells in Jupyter notebook.
Fugue decouples logic and execution, making it easy for users to specify the execution engine during runtime. This empowers heavy SQL users by allowing them to express their logic indepedent of a compute framework. They can easily migrate workflows to Spark or Dask when the situation calls for it.
There are a lot of details and features that can’t be covered in one blog post. For an end-to-end example, visit the Kaggle notebook that we prepared for Thinkful data analyst bootcamp students.
Setup in Notebooks
Fugue (and FugueSQL) are available through PyPI. They can be installed using pip (installation of Dask and Spark are separate).
pip install fugueInside a notebook, the FugueSQL cell magic %%fsql can be used after running the setup function. This also provides syntax highlighting for SQL commands.
python1from fugue_notebook import setup
2setup()
Contact Us
If you’re interested in using FugueSQL, want to give us feedback, or have any questions, we’d be happy to chat on Slack! We are also giving workshops to data teams interested in applying FugueSQL (or Fugue) in their data workflows.
FugueSQL is just one part of the broader Fugue ecosystem. Fugue is an abstraction layer that allows users to write code in native Python, and then execute the code on Pandas, Spark, or Dask without code changes during runtime. More information can be found in the repo above.