Motivation
Data science teams often invest in a common set of tools and build a shared Python library. This library includes common ways to clean and transform data, as well as utility functions for machine learning (such as custom metrics or specific train-test splits).
Having such a library provides a foundation to get new projects off the ground faster. Ideally, the shared library continues to grow and mature as more projects are undertaken by the team.
While having a shared library is great in concept, there are some hiccups when using the same code throughout different settings. There are various use cases that call for different tools. Some datasets can be approximately tens of thousands of rows, and some can be in the hundreds of millions of rows. Big data often calls for Spark to leverage distributed compute. However, if a project is small enough to do on Pandas, there is no need to use a cluster and add the overhead of using Spark. As expected though, using two frameworks causes issues when maintaining a shared library. Functions developed in one framework will not work readily for another.
Differences in Pandas and Spark
To demonstrate how the different frameworks syntactically differ, below is an example use case. As with any data science work, there are cases where data is missing and we try to fill it. In the table below, we’re interested in using someone’s home state. If the home state is not available, we get the work state. If the work state is also not available, we’ll attempt to use the phone number area code to infer the state.
| id | home_state | work _state | phone |
|---|---|---|---|
| “A” | “IL” | “IL” | “217-123-4567” |
| “B” | None | “WI” | “312-123-4567” |
| “C” | “FL” | “FL” | “352-234-5678” |
| “D” | “CA” | “CA” | “415-345-6789” |
| “E” | None | None | “217-123-4567” |
| “F” | “IL” | None | “312-234-5678” |
The Pandas and Spark implementations for the problem above can be seen in the Github Gist below. For a relatively simple transformation, the code already looks very different between Pandas and Spark. More than the syntax, the bigger problem is that we have a piece of custom business logic that can’t be recycled between Pandas and Spark applications.
python 1# Comparison of creating inferred_state column
2
3area_to_state = {"217": "IL", "312": "IL", "415": "CA", "352": "FL"}
4
5# Pandas implementation
6
7df['inferred_state'] = df['home_state']\
8 .fillna(df['work_state'])\
9 .fillna(df['phone'].str.slice(0,3).map(area_to_state))
10
11# Spark implementation
12from pyspark.sql.functions import coalesce, col, substring, create_map, lit
13from itertools import chain
14
15mapping_expr = create_map([lit(x) for x in chain(*area_to_state.items())])
16df = df.withColumn('inferred_state',
17 coalesce('home_state',
18 'work_state',
19 mapping_expr.getItem(substring(col("phone"),0, 3))
20 )
21)
Being locked to a framework is compounded over time as project size increases, and as more complicated logic is involved to transform data. Eventually, the code base logic becomes tightly coupled with a framework and the overhead to switch framework cumulatively increases.
How can we recycle custom logic across Pandas and Spark? Do we need to implement two versions of each function (once for Spark and once for Pandas)? Or is there a way to separate logic from compute? Can we focus on defining the logic, and then choose the underlying engine to run it on (Spark or Pandas)?
Decoupling logic and execution allows code to be written in a scale-agnostic and framework-agnostic way. Even if the data can be handled by Pandas now, will it still be small enough 1 year from now? 2 years from now? Scale-agnostic and framework-agnostic code allows data scientists to seamlessly swap between execution engines depending on the volume of data. No rewrite would be needed to recycle code for Spark.
Spark and Pandas Compatible Code with Fugue

This is where Fugue comes in. Fugue is an open-source framework that serves as an abstraction layer that adapts to different computing frameworks. It unifies core concepts of distributed computing and decouples the logic from frameworks used to process data (such as Spark, Pandas, Dask).
Fugue adapts to users rather than the other way around.
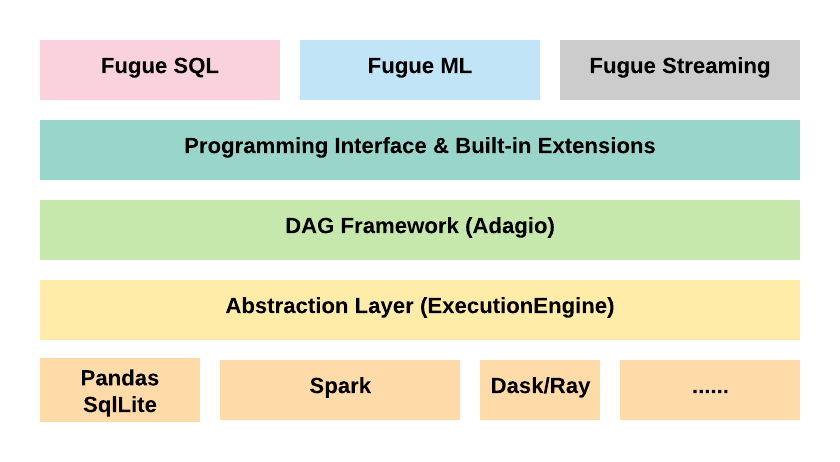
It also aims to democratize distributed computing and make it more accessible to people less familiar with Spark. By using Fugue, users can write code in native Python, and then easily port it over logic to Spark or Dask, instead of having to rewrite the code.
Fugue Example
Let’s revisit the example above and solve it in native Python and Fugue.
python 1# Import statements
2from fugue import FugueWorkflow, SparkExecutionEngine
3from typing import List, Any, Dict, Iterable
4
5# Area code to state
6area_to_state = {"217": "IL", "312": "IL", "415": "CA", "352": "FL"}
7
8# schema: *, inferred_state:str
9def fill_location(df:Iterable[Dict[str,Any]]) -> Iterable[Dict[str,Any]]:
10 for row in df:
11 potential_values = [row["home_state"], row["work_state"], area_to_state[row["phone"][0:3]]]
12
13 # Return first non-null value. Returns None if all are None.
14 row["inferred_state"] = next((val for val in potential_values if val is not None), None)
15 yield row
16
17with FugueWorkflow() as dag:
18 df = dag.df(df).transform(fill_location)
The first thing to notice in the code example is the function defined from lines 9–16 is written in base Python and has no Fugue dependencies. All data types used are native Python. The function is pure logic without the influence of Pandas or Spark.
The second thing is the schema hint in line 9. Schema is enforced in Fugue, which forces more explicit and descriptive code. Should a user move away from Fugue, this function can still be modified to work on Pandas or Spark with an apply statement. The schema hint will just stay as a comment, but still be useful.
The last thing to note is the FugueWorkflow context manager defined in line 18. The default execution engine is Pandas but if we want to bring the entire workflow to Spark, we can do it with a one-line change.
python1with FugueWorkflow(SparkExecutionEngine) as dag:
Now everything inside the FugueWorkflow context manager will run in Spark.
Fugue Benefits
The benefits of Fugue scale as your workflow complexity increases. The most evident benefit is that the same logic will work for both Pandas and Spark jobs. For teams that have rapidly growing requirements, this gives us flexibility and agility to adapt to a higher volume of data seamlessly. Even if a data science team can handle current volumes of data in Pandas, there is still a possibility to eventually need Spark. With Fugue, the transition is effortless because changing the computation engine requires one line of code change.
In addition, Fugue lets users prototype on more manageable data and scale up reliably when needed. This has the potential to increase developer productivity and reduce cluster cost. The execution engine can be swapped when ready to test code on the full dataset. Spark jobs easily cost hundreds of dollars in cluster cost per run. This saves money as clusters do not need to be spun up to test code.
Lastly, Fugue allows users to write unit tests for smaller and more testable functions. The logic is explicit and independent from frameworks. This enforces a more maintainable codebase.
Difference Between Fugue and Koalas
Databricks has a library called Koalas that allows Pandas users to use the same DataFrame API on top of Spark. For some cases, changing the import statement will allow users to change from a Pandas execution to a Spark execution.
One concern here is that not all Pandas functions are implemented in Koalas, which means that some Pandas-written code will not work instantly just by changing the import statement.
Even if the functions were implemented, there are differences between Pandas and Spark that are difficult to reconcile. For example, Pandas allows for mixed-type columns (containing both integers and strings), while Spark DataFrames don’t. Using Koalas with mixed types will cause errors. Fugue follows Spark, and Apache Arrow, in having strong and explicit typing.
Conclusion
We have seen how Fugue can be used to create Python functions, capable of being used across Pandas and Spark with no changes. This removes the need to maintain two versions of each function and also decouples the logic from the underlying execution engine.
Writing a codebase in Fugue allows users to change between Pandas and Spark with one line of code change.
Contact Us
If you’re interested in using Fugue, want to give us feedback, or have any questions, we’d be happy to chat on Slack! We are also giving more detailed workshops to data teams interested in applying Fugue in their data workflows.