Photo by Pablo Arroyo on Unsplash
Note: The code presented is in images for formatting purposes but can all be found here.
Motivation
While Pandas is the most common Python tool for data science and data analyst workflows, it doesn’t scale as well to handling big datasets as it only uses one core at a time. It also uses a surprising amount of memory. In Wes McKinney’s blog post, he mentions that the rule of thumb is to have 5x or 10x as much RAM as the size of your dataset.
When data processing gets inefficient on Pandas, data scientists start to reach for distributed computing frameworks such as Spark. These frameworks speed up computation by using available cores on a single machine or even across the cluster. The downside is that in order to take advantage of Spark, Pandas and Python code normally have to be wrangled to be compatible with Spark.
In this article, we’ll go over an example of seamlessly porting Pandas and Python code to Spark with Fugue, an open-source abstraction layer for distributed computing. After going through the Fugue method, we’ll compare it to the traditional approach using Spark’s mapInPandas method, available in Spark 3.0.
Example Problem
In this sample problem, we have a machine learning model that is already trained using Pandas and scikit-learn. We want to run predictions on a dataset that is too big for Pandas to efficiently handle using Spark. This tutorial will also apply to operations that transform the data. We are not limited to machine learning applications.
First, we start by making a simple LinearRegression model.
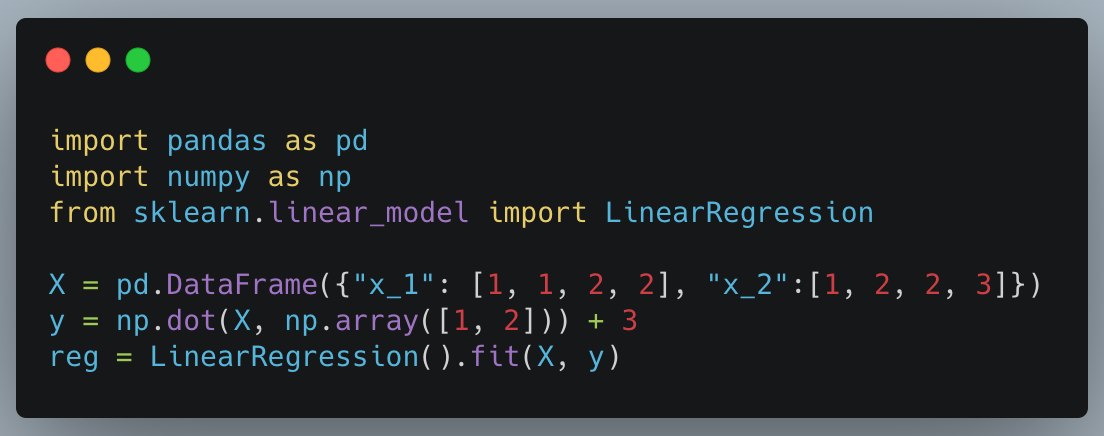
And then we make a simple predict function that will take in a DataFrame and create a new column called “predicted” with the predictions. This part is nothing new for Pandas users.

Executing in Spark with Fugue
This is where the magic happens. Fugue is an abstraction layer designed to enable users to port Pandas and Python code to Spark. Later on, we’ll show how to do it manually without Fugue, but first, we’ll look at how Fugue accomplishes this.
Fugue has a transform function that takes in Pandas or Spark DataFrames and a function. When we specify an ExecutionEngine, Fugue will then apply the necessary conversions to run the code on that engine (Spark in this case). If there is no engine specified, it will run on Pandas. See the code snippet below.
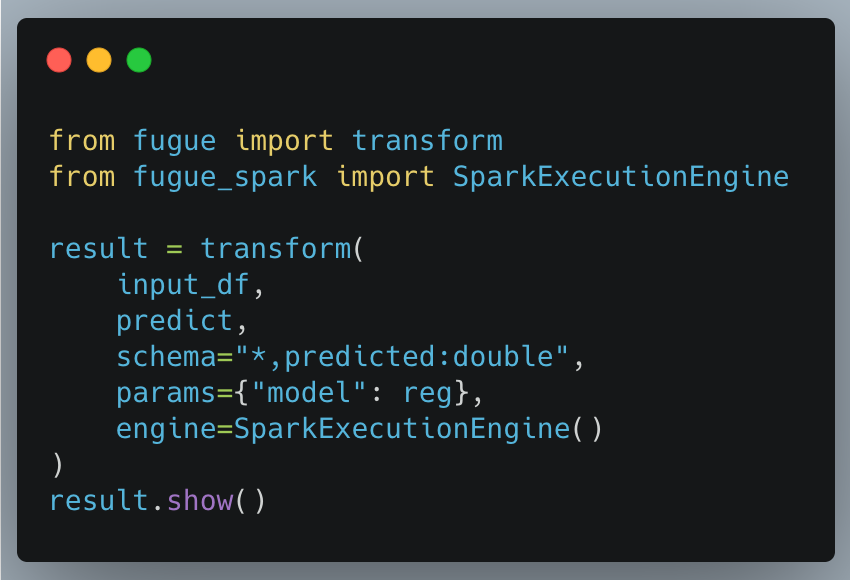
And that’s literally it. This will run on Spark. Most things in the code block will be easy to understand. input_df can be either a Pandas or Spark DataFrame. The predict function is the one we defined earlier, and the params argument contains what is passed to that function. In this case, we passed the regression model that we trained earlier. Because we chose the SparkExecutionEngine, all of the code will run on Spark in a parallel fashion.
The last thing to understand is the schema parameter. This is because the schema is strictly enforced in Spark and needs to be explicit. With “*, predicted:double”, we specify that we are keeping all columns and adding a new column called predicted of type double. This is a massively simplified syntax to the Spark approach as we’ll see later.
Using the transform function from Fugue, we were able to use a Pandas function on Spark without making any modifications to the original function definition. Let’s see how to do the equivalent without Fugue. There is no need to fully understand everything in the next section, the point is just to show how much simpler Fugue’s interface is.
Spark Implementation
This section is for people who want to compare the approaches. The following code snippet is how to do it using Spark’s mapInPandas:
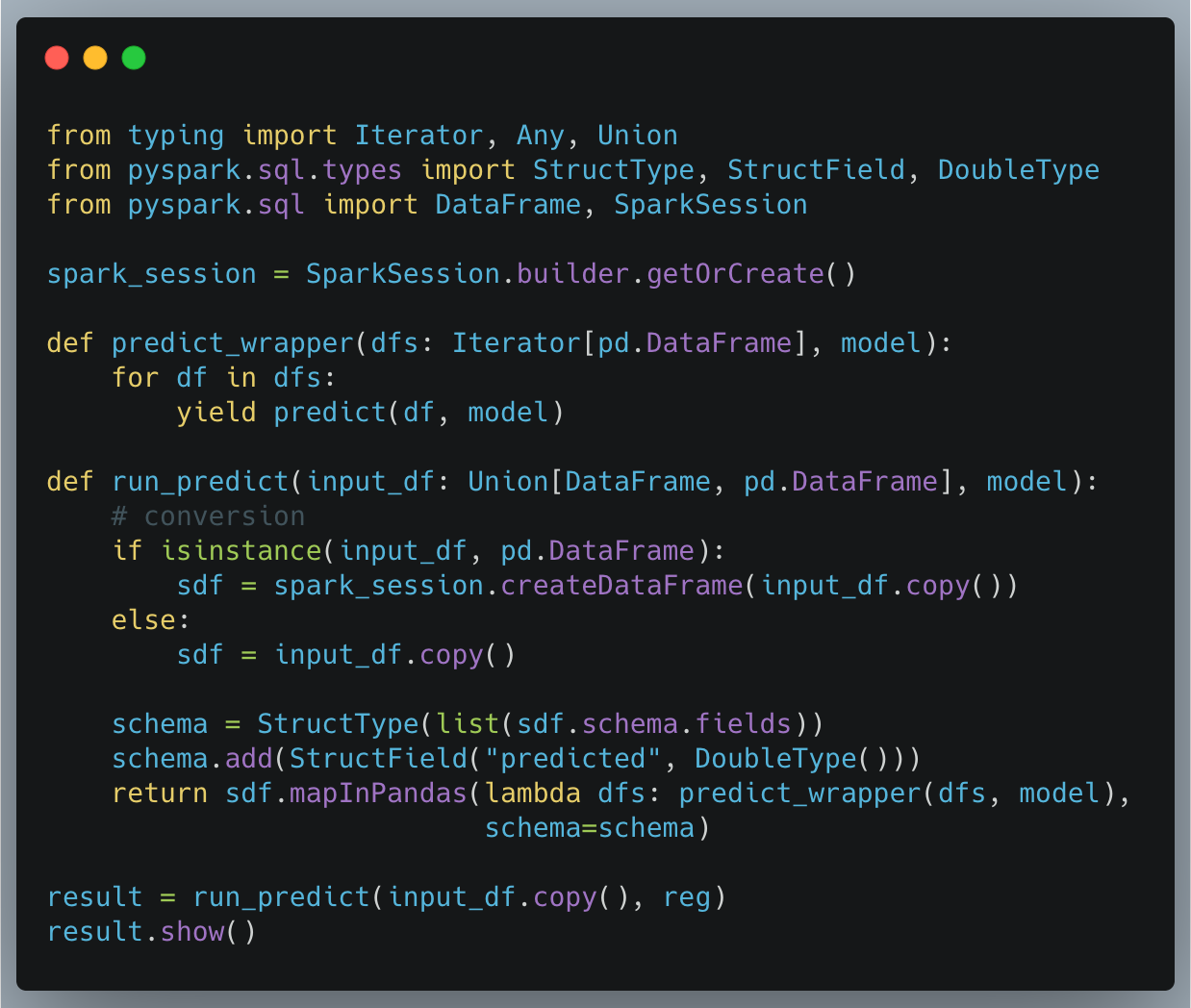
In order the steps are:
- Create the SparkSession (Fugue’s SparkExecutionEngine does this under the hood)
- Wrap the predict function to work on an Iterator of DataFrames. This is because the function will take in multiple DataFrames (partitions) and predict each set.
- Create a run_predict function that takes in either a Spark or Pandas DataFrame. Convert the DataFrame to a Spark DataFrame if it is not already.
- Pull the Schema and add the new “predicted” column of type double.
- Map the operation to the partitions using the mapInPandas method.
Fugue’s transform takes care of all of this for the user.
Conclusion
In this article, we have compared two ways to bring Pandas and Python functions to Spark. The first was with Fugue, where we simply invoked the transform function on the SparkExecutionEngine and all of the conversion was handled for us. The second was using vanilla Spark, where we had to create helper functions.
For one function, we already had to write a lot of boilerplate code in the Spark implementation. For a codebase with tens of functions, practitioners end up writing a significant amount of boilerplate code that clutters the codebase. While the simplest way to use Fugue is the transform function, this concept of writing code compatible with both Pandas and Spark can be extended to full workflows. For more details, feel free to reach out (information below).
Contact Us
If you are interested in learning more about Fugue, distributed computing, or how to use Spark in a simpler way, feel free to reach out! The content covered here is just the starting point. The Fugue team is giving full workshops and demos to data teams and would love to chat with you.