In a previous article, I wrote about FugueSQL as a SQL interface on top of Spark, Dask, and Pandas DataFrames. For those familiar with SparkSQL, FugueSQL is largely based on it, but with enhanced features to make it a first-class grammar for distributed computing workflows. When using SparkSQL, users often find that SQL-code is surrounded by predominantly Python code that occasionally invokes SQL. With FugueSQL, the other approach is supported where you can have predominantly SQL code that invokes Python.
In this walkthrough, we’ll show how to run FugueSQL on top of Spark through Databricks. There is a handful of steps, and it can honestly be quite tricky. You can reach out to me on the Fugue Slack channel for questions.
Motivation
The article linked in the intro gives an introduction about FugueSQL, so we’ll just show it briefly here. The following code snippet is a cell in a Jupyter Notebook. Notice the cell magic %%fsql makes this cell into a FugueSQL cell. The spark keyword after indicates to run this on the Spark Execution Engine.

A useful feature about FugueSQL is how easy it is to swap out the ExecutionEngine. If a user specifies %%fsql without spark, the execution will use the Native ExecutionEngine, which is based on Pandas. By adding or removing the Spark keyword, we can toggle between local execution and cluster execution.
The local execution is straightforward, but getting Spark up and running is new to some users. So in this guide, we show how to do it and how to link FugueSQL to Spark (Hint: Most of the work is setting up Databricks).
Outline
We will go over this process in the following steps:
- Setting up Databricks cluster
- Installing and configuring databricks-connect
- Using FugueSQL with a Spark backend
If you are already familiar with a certain step, you can skip it and move on.
Getting Databricks Set-up
Databricks is available across all three major cloud providers (AWS, Azure, GCP). Actually getting Databricks onto your account will vary a bit between these. In general, it will involve going to the Marketplace of your cloud vendor, and then signing up for Databricks.
The process with different cloud providers will slightly differ, but the important thing to look for is to create a workspace. For more information, you can look at the following cloud-specific documentation.
- https://databricks.com/product/aws
- https://databricks.com/product/azure
- https://databricks.com/product/google-cloud
The picture below is what entering a workspace will look like.
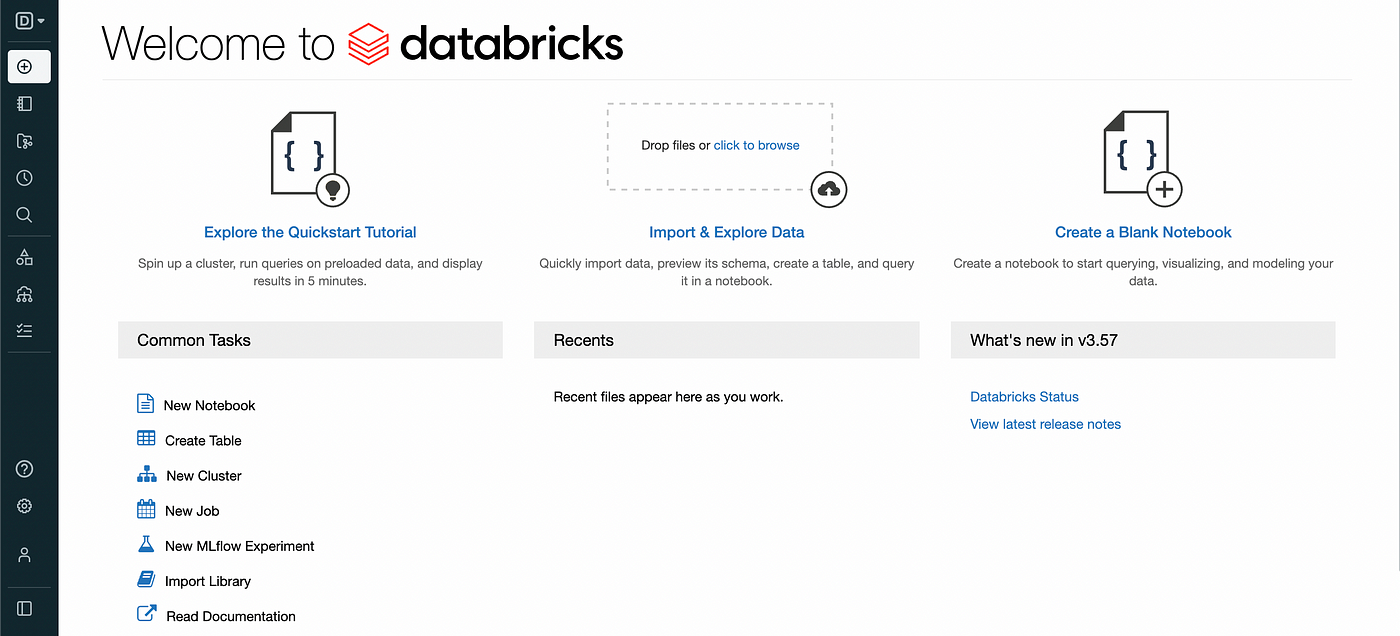
From here, you can create a cluster by clicking the “New Cluster” link. The cluster will serve as the backend for our Spark commands. With the databricks-connectpackage that we will use later, we can connect our laptop to the cluster automatically just by using Spark commands. The computation graph is built locally and then sent to the cluster for execution.
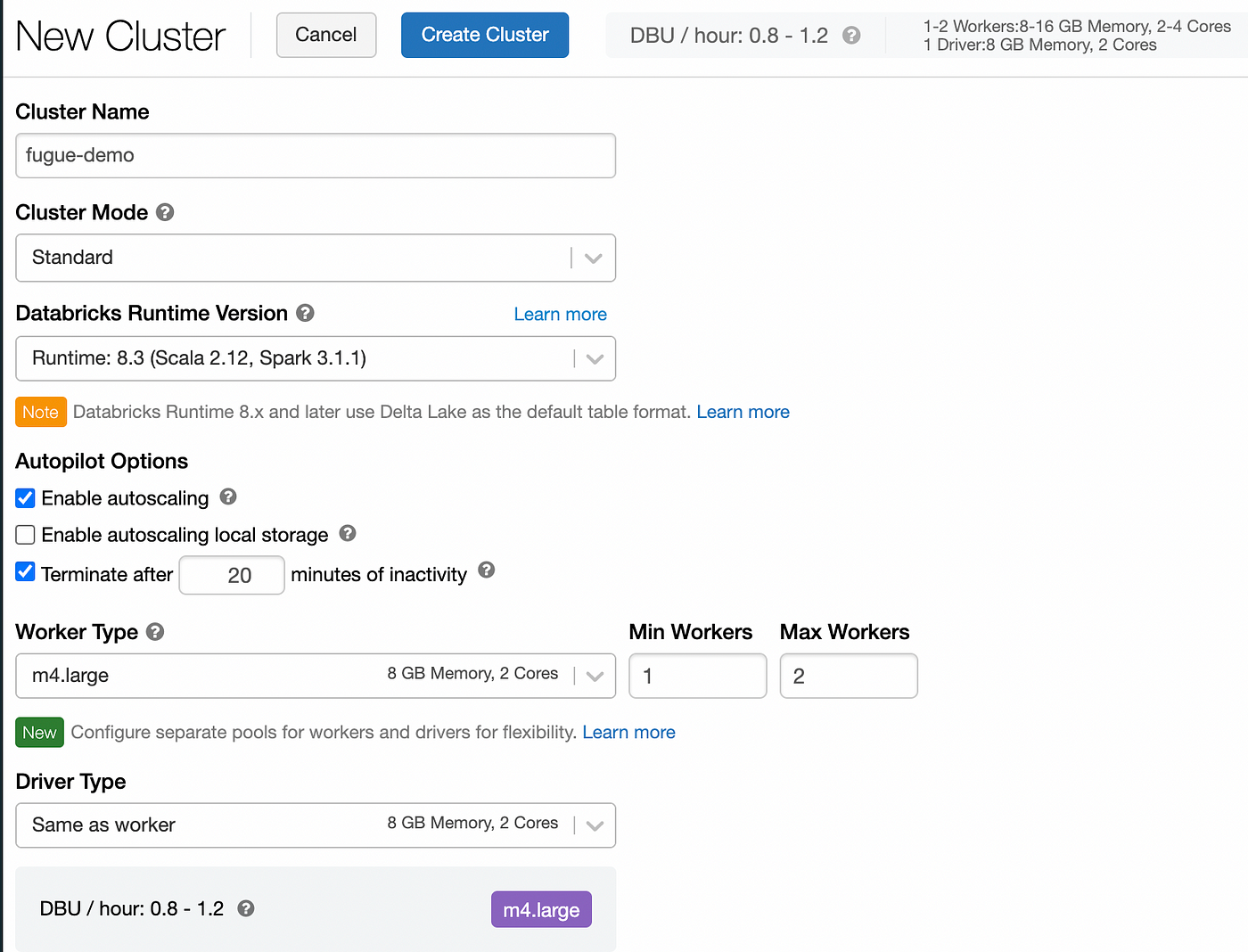
Creating a cluster on Databricks
Note when creating a cluster that you can start out by reducing the Worker Type. Clusters are very expensive! Be sure to lower the worker type to something reasonable for your workload. Also, you can enable autoscaling and terminating the cluster after a certain number of minutes of inactivity.
Installing Libraries
Now that we have a cluster, we just need to make sure to install fugue in order to be able to use fugue commands on the cluster. In order to do this, you can add the library through the UI.
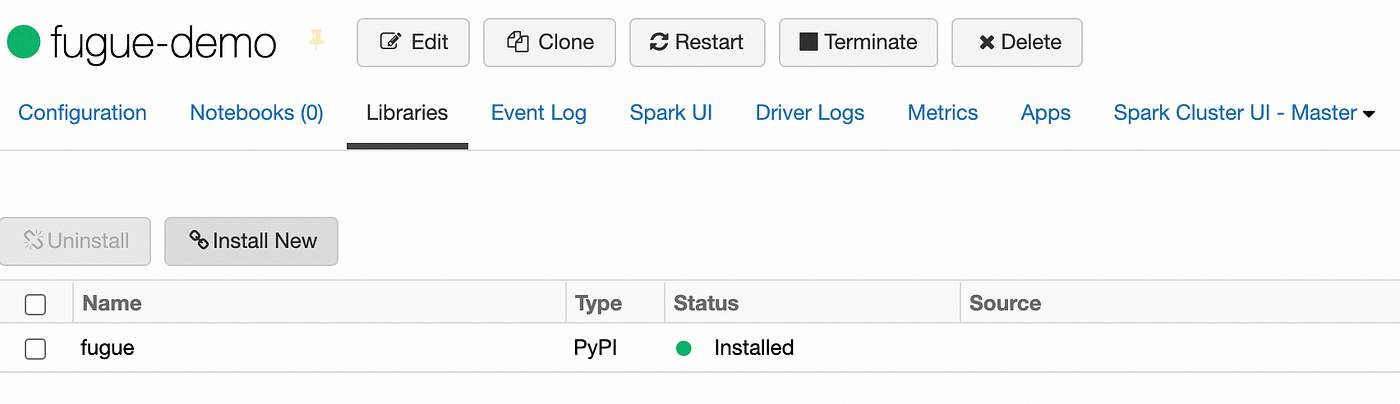
Databricks-connect
Installing databricks-connect
Databricks-connect is a library that Databricks provides to run Spark commands on the cluster. The content here will just be a summary, but the full guide to installing databricks-connect can be found here.
In general, you need to install the databricks-connect library using pip install. This can be done with the following commands.
pip uninstall pyspark
pip install databricks-connect
Note that you are uninstalling pyspark because it conflicts with databricks-connect. databricks-connect will hijack your pyspark installation such that doing:
import pyspark
will load the databricks-connect version of PySpark. This is how it sends Spark commands to the Spark cluster.
The other important thing is that the version of your library must match the Databricks Runtime Version of your cluster. Otherwise, you will run into errors and the code will not be able to execute correctly. For example, I used the Runtime 8.3 when creating a cluster above so my databricks-connect version must be exactly 8.3.x as well.
Configuring the cluster
Now that you have a cluster created from the first step and databricks-connect installed, you can configure the cluster by doing databricks-connect configure . There are more details where to get the relevant pieces of information in their documentation here. For my example on AWS, it looked like this:

You can verify if this worked by using databricks-connect test , and then you should see a message that all tests passed.
FugueSQL on top of Databricks
If everything worked in the previous steps, FugueSQL with a Spark backend will “just work”. This is because FugueSQL uses the same pyspark installation that you have on your machine. So we can now spin up a Jupyter Notebook and run a simple command. This may take a while to execute because it will spin up your Databricks cluster in the background which can take more than 5 minutes.
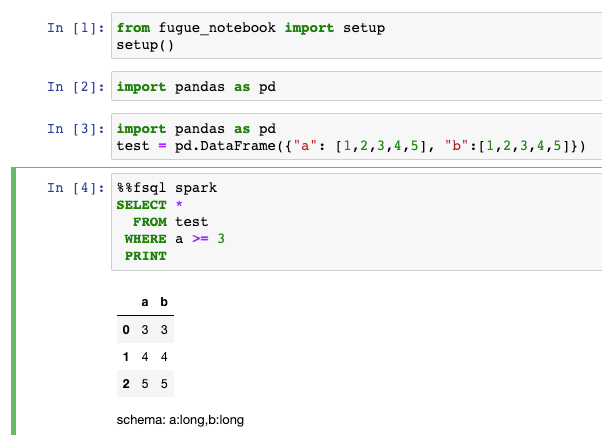
This command should have turned on your Spark cluster in Databricks and then run the command. Now we can also use more complex FugueSQL functionality on top of Spark. For example, we can apply a Python function in the SQL as follows.
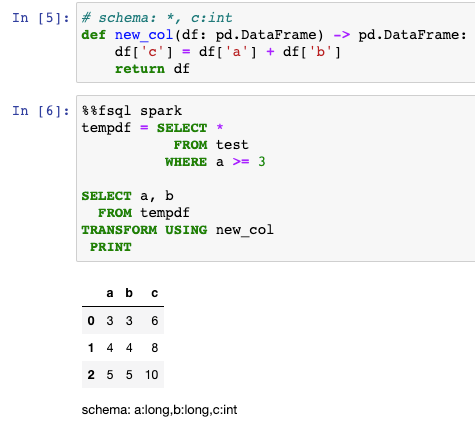
Conclusion
In this walkthrough, we have set up a Databricks cluster and configured our local Spark settings to use that cluster. In doing so, we can use FugueSQL with Databricks as our backend. This can even be extended to working with data that lives on AWS S3 or Azure Data Lake.
Contact
For any questions or if you are new to Fugue, feel free to reach out to me through the Fugue Slack.