Fugue is an open-source library that provides a unified interface for Pandas, Spark, and Dask DataFrames. In this article, we will show how Fugue can accelerate the development of big data projects by decreasing compute costs and by increasing developer productivity.
First, we’ll go over a simple code example that will highlight some of the complexities introduced when using Spark, and then show how these can be abstracted by using Fugue.
Motivating Example
Problem setup
First, we’ll look at a motivating example where we have a pandas DataFrame with one column containing phone numbers. For each phone number, we want to get the area code (in the parenthesis of the phone number), and then map it to a city as a new column.
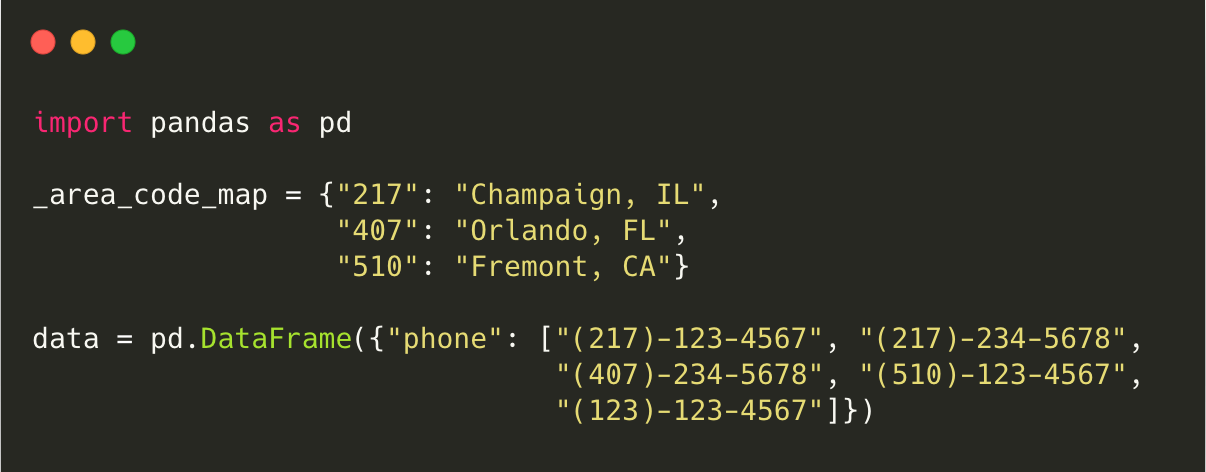
Pandas implementation
Pandas has a very elegant solution for this. We can use the map() method of the phone column.

This yields the following DataFrame:
| phone | city | |
|---|---|---|
| 0 | (217)-123-4567 | Champaign, IL |
| 1 | (217)-234-5678 | Champaign, IL |
| 2 | (407)-234-5678 | Orlando, FL |
| 3 | (510)-123-4567 | Fremont, CA |
| 4 | (123)-123-4567 | NaN |
Spark implementation
But what happens when the DataFrame is too big and we need to bring this logic to Spark? It will look like the following (in Spark 3.0 and above). No need to digest what is going on here. This is just to show that the syntax will differ.

The issue in detail
So here we already see a problem. For the same piece of logic, we have a significantly different syntax for implementing it. This is a very common scenario where users have to write a lot of new code to bring a Pandas function to Spark.
This means two things:
- There is a duplicated effort to reimplement the same business logic on both Pandas and Spark
- Data science frameworks couple logic and execution together. Pandas code can be brought to Spark (with heavy modifications we’ll see later), but Spark code can only be executed on the Spark engine.
Fugue transform
Fugue aims to address this by making the same code executable across Pandas, Spark, and Dask. The simplest way to use Fugue is the **transform** function, which takes a Python or Pandas function, and brings it to Spark and Dask.
For the example above, we can wrap the Pandas code into a function. There is nothing fancy going on.

But just by doing this, we can now bring it to Spark and Dask using the transform function of Fugue. The example below is to bring it to Spark.

This will return a Spark DataFrame (and can take in both Pandas and Spark input DataFrames). To use the map_phone_to_city function on Pandas, users can simply use the defaultengine. The schema argument is the output schema of the operation, a requirement for distributed computing frameworks. Similarly, there is a DaskExecutionEngine for Dask execution.
Decoupling of Logic and Execution
Now with this transform function, we can use the map_phone_to_city function on Pandas, Spark, and Dask. The logic is decoupled from the execution engine. Some readers may be wondering if the map_phone_to_city function is still tied to Pandas, and they would be right. If we wanted to implement it in pure native Python, we could use lists and dictionaries like in the code below.

This can be used by Fugue across Pandas, Spark, and Dask with the same transform call. Fugue will handle the conversion of the DataFrame to the type annotations specified. Here, we use the get() method of the _area_code_map dictionary and specify a default value “Unknown”. Again this can be brought to Spark by doing:

which results in
| phone | city |
|---|---|
| (217)-123-4567 | Champaign, IL |
| (217)-234-5678 | Champaign, IL |
| (407)-234-5678 | Orlando, FL |
| (510)-123-4567 | Fremont, CA |
| (123)-123-4567 | Unknown |
By using the **transform** function, we can keep our logic separate from execution and then specify the execution engine at runtime. The logic is defined in a pure scale-agnostic way.
A note on execution speed
A lot of users ask how the Fugue transform compares to the pandas_udf Spark has. The quick answer is that Fugue can be configured to use pandas_udf under the hood. For more information, see this. In this case, Fugue is mapping the code to a pandas_udf , but still providing an elegant cross-framework compatible function.
Reducing Compute Costs
Now that we have a quick way to toggle between Pandas and Spark execution by changing the engine when we call transform, we can prototype on a local machine and test code locally before scaling out to the Spark cluster. This is made possible because we are not tied to the PySpark API to define our logic. This reduces compute costs in two ways:
- Unit testing can be done locally, and then ported to Spark when ready
- There will be fewer mistakes happening on the cluster because we can do more development locally before porting to Spark. These expensive mistakes will be reduced.
A lot of Spark users use the databricks-connect library to run code on a Databricks cluster. This compiles the execution graph locally, and then sends it to the Databricks cluster for execution. The downside of this is that for any simple test with Spark code, the Databricks cluster will spin up and incur costs. By using Fugue, developers can easily toggle between local and cluster execution by changing the execution engine.
Improved Testability
Using Fugue’s **transform** reduces the amount of boilerplate code and that needs to be written when bringing a Pandas-based function to Spark. The code below is an example of bringing our previous map_phone_to_city function to Spark.
Note that this code will only work for the Panda-based implementation, it will not for the native Python implementation that used Listand Dict. Again, no need to fully understand the code, the point is just to show the amount of boilerplate code introduced.
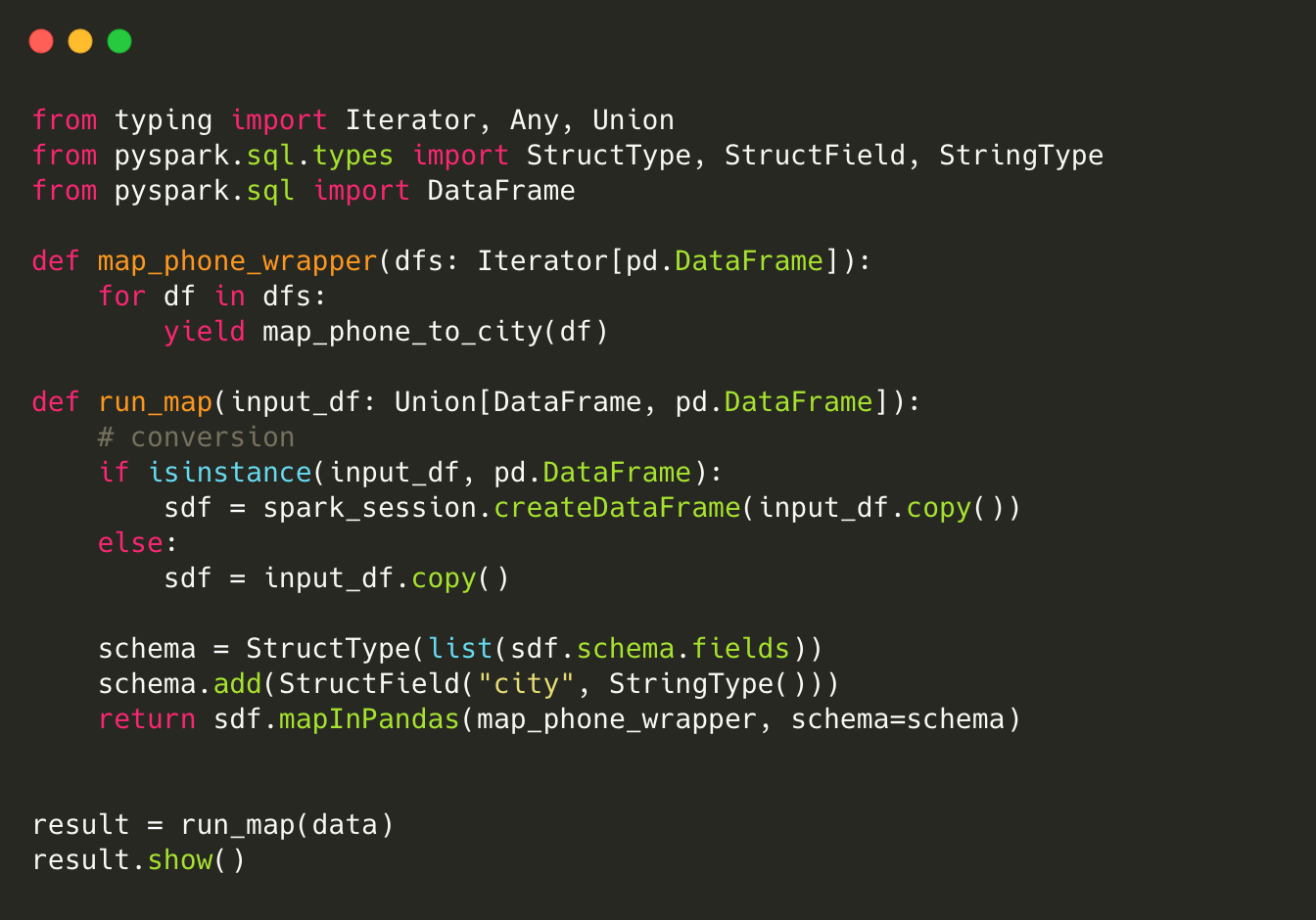
You will notice that this code is coupled with Spark and you need to run Spark hardware for testing. From a unit testing standpoint, you need to test two additional functions to bring your function to Spark. For Fugue’s transform , you just need to unit test the original function because transform is heavily tested by Fugue.
The transform function is also easily testable if you want to further test it. Simply call assert and test the inputs and outputs.
Increasing Developer Productivity
Using Fugue, developers can prototype easily in a scale agnostic way and catch errors quicker, making development significantly faster. But there are also benefits from using Fugue:
- Unit testing is decreased (as seen above) and there is less boilerplate code
- Developers can express their logic in a way that is comfortable to them (Python or Pandas)
- Maintenance of Spark applications is easier
- Functions can be reused between Pandas and Spark projects
Maintenance of applications
One of the harder things about big data projects is maintenance. Inevitably, the code will have to be revisited in the future to change some business logic or fix a bug. If the codebase is coupled to the Spark API, that means only people who know Spark can maintain it.
Fugue reduces the need for specialized maintenance by moving the logic to Python or Pandas, which are more accessible by data professionals. The code becomes more modular and readable, which means that maintaining big data applications becomes easier.
Reusability of logic
Often, data science teams will simultaneously have some projects that don’t need Spark and other projects that demand Spark. In this scenario, business logic has to be implemented twice, once for each framework to be used across both sets of projects. This complicates maintenance as there are more places to edit the code when changes are needed. Fugue’s transform solves this by making the code agnostic to the execution engine.
If data teams circumvent this problem by using Spark for everything or Pandas for everything, then there is an issue of using the wrong tool for the job. Using Pandas on big data requires expensive vertical scaling, and using Spark on smaller data introduces unnecessary overhead. Fugue lets users define logic first, and then choose the execution engine at runtime. This decreases engineering time spent on porting over custom business logic.
Conclusion
In this article, we have shown how the Fugue transform function can be used to bring a single function to Pandas, Spark, or Dask. This seamless transition allows quick toggling between local execution and cluster execution. By maximizing the amount of prototyping that can be done locally, we can make big data projects cheaper by increasing developer productivity and decreasing hardware costs.
The transform function is just the start of Fugue. For more information, check the resources below.
Resources
For any questions about Fugue, Spark, or distributed compute, feel free to join the Fugue Slack channel below.