There is now a native integration between PyCaret and Fugue that distributed the training of models. It will be documented in PyCaret 3.0
Photo by Hannes Egler on Unsplash
PyCaret is a low code machine learning framework that automates a lot of parts of the machine learning pipeline. With just a few lines of code, several models can be trained on a dataset. In this post, we explore how to scale this capability by running several PyCaret training jobs in a distributed manner on Spark or Dask.
PyCaret Model Score Grid Example
First, we go through a simple PyCaret classification example. Most of this code was taken from this tutorial in the PyCaret documentation. The point is to show how we can generate the model leaderboard with a few lines of code.
We load in the Titanic dataset by using the get_data function. This is a well-known classification dataset.
python1from pycaret.datasets import get_data
2df = get_data("titanic")
This will give us the following data. In this example, we are concerned with creating a model to predict if a passenger survived.

Now we can use PyCaret for our model training. There are three function calls in the next code block to train the models and retrieve their metrics for our dataset.
python 1from pycaret.classification import *
2
3clf = setup(data = df,
4 target = "Survived",
5 session_id = 123,
6 silent = True,
7 verbose = False,
8 html = False)
9
10models = compare_models(fold = 5,
11 round = 4,
12 sort = "Accuracy",
13 turbo = True,
14 n_select = 5,
15 verbose = False)
16
17results = pull().reset_index(drop = True)
A brief explanation for each function call:
- The
setupinitializes the environment and creates the transformation pipeline to run. compare_modelsruns a couple of model training runs and scores them with stratified cross-validation. This returns the top models based onn_select. A value of 5 returns the top 5 trained models.pullwill get the score grid DataFrame for us. Below is an example of what it looks like (first 5 rows sorted by accuracy).
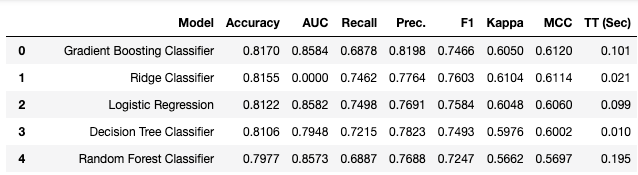
In a bit, we will look at how we can run multiple compare_models calls parallelized distributedly with Spark or Dask. Before that, we will look at how to bring an individual function to Spark or Dask.
Wrapping the PyCaret Code
Fugue is an open-source framework that ports Python, Pandas, or SQL code to Spark or Dask. In this blog, we will look at the transform function. This takes a single function and executes it on Spark or Dask on each partition of data.
We’ll start by wrapping our PyCaret code inside a function named wrapper . This wrapper function will be used on each partition of data in Spark. Inside the wrapper is basically all the code we had earlier. The only new things will be resetting the index and renaming the columns. This is because Fugue needs the column names to not contain spaces and periods to be compatible with all backends.
Note that the type annotations of the function (pd.DataFrame) are required for Fugue to know how to bring the function to Spark or Dask. This is because Fugue can handle a lot more annotations such as List[Dict[str, Any]] or Iterable[List[Any]]. Schema is also required in the transform function because Spark and Dask require (or significantly benefit from) explicit schema.
python 1from fugue import transform
2import pandas as pd
3
4schema = """Model:str, Accuracy:float, AUC:float, Recall:float, Prec:float,
5F1:float, Kappa:float, MCC:float, TT_Sec:float"""
6
7def wrapper(df: pd.DataFrame) -> pd.DataFrame:
8 clf = setup(data = df,
9 target = 'Survived',
10 session_id=123,
11 silent = True,
12 verbose=False,
13 html=False)
14 models = compare_models(fold = 10,
15 round = 4,
16 sort = "Accuracy",
17 turbo = True,
18 n_select=5,
19 verbose=False)
20 results = pull().reset_index(drop=True)
21 # Fugue can't have spaces or . in column names
22 results = results.rename(columns={"TT (Sec)": "TT_Sec",
23 "Prec.": "Prec"})
24 return results.iloc[0:5]
25
26res = transform(df, wrapper, schema=schema)
Now we have a basic function that can be used with native Pandas. Calling the transform function will give us the same results as the score grid earlier. By testing it on Pandas, we know that this code will work when we port it on the Spark execution engine. But before bringing it to Spark, we will partition the data first in the following section.
Machine Learning on Spark and Dask
Machine Learning on big datasets takes two forms. The Dask-ML documentation provides a good explanation of these. The first is memory-bound problems where the dataset does not fit on a single machine. In this case, one large model is being trained across the cluster. The second is compute-bound problems where multiple models are trained on data that fits on a single machine. The cluster is used to parallelize multiple smaller model training jobs.
When data is too big to fit on a single machine, it normally means that there are logical groupings of data that can be used to split the problem into several smaller machine learning problems. In this Titanic example, we will split the data by sex (male or female), and then run the PyCaret compare_models for each group of data.
Porting the PyCaret Code to Spark and Dask
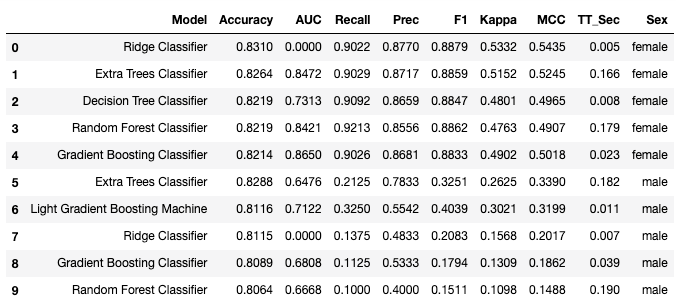
The following code will split the data into male and female, and then for each group, run compare_models . The twocompare_models function calls will run distributedly on Spark. First, we’ll first show the code and output, and then we’ll go through the changes to bring our wrapper to Spark.
Running PyCaret Distributedly on Spark
This gives us the top 5 models and the metrics for both groups (male and female). For this specific problem, we saw a slight increase in performance. This was probably limited because of the data size. However, with big datasets, this method can often yield significant improvements compared to training one big model over the whole dataset.
python 1import fugue_spark
2
3schema = """Model:str, Accuracy:float, AUC:float, Recall:float, Prec:float,
4F1:float, Kappa:float, MCC:float, TT_Sec:float, Sex:str"""
5
6def wrapper(df: pd.DataFrame) -> pd.DataFrame:
7 clf = setup(data = df,
8 target = 'Survived',
9 session_id=123,
10 silent = True,
11 verbose=False,
12 html=False)
13 models = compare_models(fold = 10,
14 round = 4,
15 sort = "Accuracy",
16 turbo = True,
17 n_select=5,
18 verbose=False)
19 results = pull().reset_index(drop=True)
20 # Fugue can't have spaces or . in column names
21 results = results.rename(columns={"TT (Sec)": "TT_Sec",
22 "Prec.": "Prec"})
23 results['Sex'] = df.iloc[0]["Sex"]
24 return results.iloc[0:5]
25
26
27res = transform(df.replace({np.nan: None}), wrapper, schema=schema, partition={"by":"Sex"}, engine="spark")
28res = res.toPandas()
To bring PyCaret to Spark, we had to make the following changes to our wrapper function:
- add Sex to the schema. Distributed computing frameworks are strict on the schema.
- add a column called Sex to the results. This is for tracking when we collect all the results. Because the data is pre-partitioned because the
wrapperfunction is called, we are guaranteed to have a uniform value in the Sex column (either male or female).
Then we made the following changes to the transform call:
- Replace np.nan with None in the original DataFrame. Spark can have difficulty interpreting a column with both np.nan and string values.
- Added a partition by Sex to split the data into two groups
- Imported fugue_spark and used the “spark” execution engine for Fugue.
Conclusion
In this article, we showed how to leverage Spark to execute PyCaret model training on multiple partitions of data simultaneously. Since the writing of this article, the PyCaret team and Fugue team are working on a more native integration to distribute thecompare_models function over Spark or Dask. The progress of that can be tracked on Github.
Data License
The Titanic dataset is hosted by PyCaret under the MIT license.