Written by Kevin Kho and Han Wang
This is a written version of our most recent Spark Data + AI Sumit talk.

SQL-like Frameworks for Distributed Computing
In our last article, we talked about the limitations of using the Pandas interface for distributed computing. Some people quickly assumed that we are pro-SQL, but that is not exactly true either. Here, we’ll look at traditional SQL and the pain points of using it as the grammar for big data workflows. None of these will be too surprising to active SQL users, but discussing them will show the tradeoffs of using SQL as opposed to Python.
The data community is often polarized between SQL versus Python. People who love the functional interface Pandas and Spark provide are often quick to point out how SQL can’t do more complicated transformations or require many more lines of code. On the other hand, SQL users find SQL to be more expressive as a language. In the last section of this article, we’ll show that these tools are not mutually exclusive and we can leverage them together seamlessly through Fugue.
SQL is Often Sandwiched by Python Code
When we talk about SQL in this article, we are referring to tools such as DuckDB, or for big data, tools like SparkSQL and dask-sql. The last two are interfaces that allow SQL-lovers to express computation logic in a SQL-like language, and then run it on top of the respective distributed computing engines (Spark or Dask).
But even if these SQL interfaces exist, they are often invoked in between Python code. Take the following documentation of Spark (also seen in the image below), Python code is still needed to perform a lot of the transformations or loading of the DataFrame and for post-processing after the SQL query. This is because standard SQL doesn’t have the grammar to express a lot of the operations distributed computing users perform. Currently, SQL is inadequate for expressing end-to-end workflows.
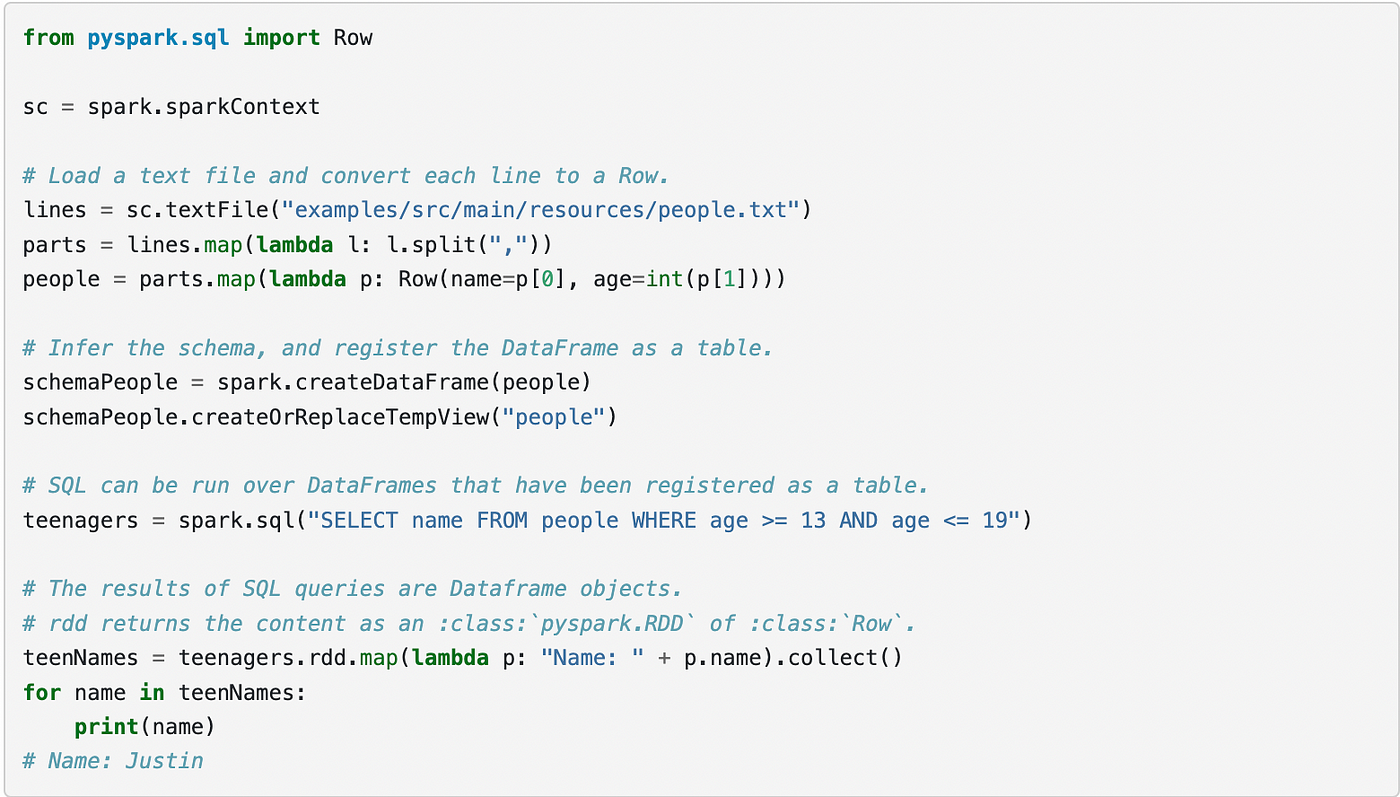
There is a lot of Python code to understand for users that predominantly want to use SQL. SQL is often relegated to a limited portion of the workflow. We’ll look more closely at SQL’s shortcomings through a concrete example.
Example Data and Query
Take the following DataFrame composed of multiple timeseries, there are three columns. The first column refers to a grouping, the second column refers to ordering (you can think of it as a datetime), and the last column refers to the value of concern.
Take the following query shown below. There is no need to really dig in and understand it. If it’s already daunting, that’s because SQL can be less expressive and harder to read for more complicated operations. We’ll break it down in the next section.
There are 5 SELECT statements in this block. In order, they do:
- Get the rolling mean and rolling standard deviated of the values
- Calculate the rolling z-score (of the records with enough warm-up) and filter out NULL records
- Get the top time series based on the outlier count
- Get the full data of the worst timeseries with an
INNER JOINto the previous z-score table - Sum the z-score values from this worst table
This operation is not designed to make complete sense. The more important thing is the structure of the query and the intermediate tables. We have an intermediate table z that is used by two downstream tables. This leads us to the first problem of traditional SQL.
Problem 1: Traditional SQL Lacks Grammar for Distributed Computing
The structure of the query above is illustrated below. The table z ends up being used by both top and worst . Because distributed computing uses lazy evaluation, operations are only computed when needed. A side effect of this is that z can potentially be recomputed twice, once for top and once for worst when using Spark or Dask.
The recomputation of z can be avoided by explicitly calling .persist() on the Spark DataFrame. But how do we persist when using the SparkSQL interface? There is no PERSIST keyword. We need to break the SQL query apart and invoke the persist call using Python before downstream portions of the query. SQL also does not have grouped map semantics.
The issue is that SQL doesn’t have keywords for distributed computing operations such as persisting or broadcasting. Without necessary grammar, the query optimization is a black box to us, and the outcome can be suboptimal (in our example, the difference is 21 sec vs 12 sec). This shows z took 9 seconds to calculate, and we could remove the duplicate computation by explicitly using a persist call.
The lack of grammar to represent these prevent us from fully utilizing the distributed computing engine unless we bring the logic back to Python.
Problem 2: SQL Traditionally Returns a Single Table
Next, a SQL query is associated with a single return. It is single-task oriented, limiting the surface area of possible operations. For example, splitting a DataFrame into two separate DataFrames is commonly used in machine learning (train-test split). This becomes impossible without breaking up a query into multiple queries, causing some redundancy.
For those familiar with Python, this would be the equivalent of returning multiple values with one function call.
Problem 3: SQL Introduces a Lot of Boilerplate Code
Another downside with SQL is that it introduces a lot of boilerplate code. The query above is already written well by using common-table expressions (CTEs) that allow it to be read from the top to the bottom. In other cases, it’s common for SQL practitioners to write queries from inside going out where inner queries are used in outer “downstream” queries. SQL practitioners often have to deal with queries that are hundreds of lines long.
Looking at the query deeper, we are not even concerned with the intermediate tables in the query above, but we have to name them anyway to reference them later. The amount of boilerplate code present detracts from being able to read the business logic spelled out by the query. This adds overhead to maintenance, especially for people who did not write the original query.
Problem 4: Modifications Create Framework Lock-in
SparkSQL enabled reading from parquet files with a modified syntax. Notice the first SELECT statement has a FROM that looks like:
sql1FROM parquet.`/tmp/t.parquet`
This is actually a Spark-specific syntax, which helps Spark users, but it creates framework lock-in. One of the advantages of SQL is that it is ubiquitous and widely adopted, but adding specific syntax reduces the portability if you want to use another SQL engine. This is the simplest example of a Spark-specific syntax that creates framework lock-in, but there are a lot more.
Traditional SQL is Hard to Iterate with on Big Data
The result of these problems is that SQL queries on big data become hard to iterate on. The pain points become magnified. Big data queries can routinely take hours, making it necessary for users to be able to iterate rapidly and cheaply.
There are three major blockers to rapid iteration when working on big data.
- How do we cache the results of expensive intermediate steps before iterating on downstream portions of a query?
- How do we run the full query on smaller data to test? And then bring it to big data seamlessly when ready?
- How do we keep operations like loading, saving, and persisting in the SQL syntax so we don’t need to frequently bring the data to Python?
The first one on the list involves tricks to juggle DataFrames between Python and SQL portions of the code, but this is still a suboptimal user experience. Relatively large SQL queries like the one above need to be split up and surrounded by more Python code. How do we avoid this and keep most of the code in SQL?
The last two on the list are close to impossible with current tools. Even if the SQL code is standard SQL and compatible across backends, our problem becomes the Python code. Again, SQL is insufficient to express end-to-end workflows alone. We resort to writing PySpark code, which is another source of framework lock-in.
FugueSQL — An Enhanced SQL Interface For Compute Workflows
FugueSQL solves these issues by extending standard SQL to make it more readable, portable, and expressive for computing workflows. FugueSQL is an open-source interface of Fugue that enables users to write end-to-end queries on top of distributed computing engines. We can re-write the SQL above into the following form using FugueSQL.

FugueSQL follows the SQL principle of being agnostic to any backend; this code is removed from any framework lock-in. Users can change between Pandas or Duckdb to Spark or Dask just by specifying the engine. The code above will run on any backend Fugue supports.
We’ll go over the changes highlighted in the query above:
LOADis now a generic operation compatible across all backends. FugueSQL also comes with aSAVEkeyword, which allows users to perform complete extract-transform-loads (ETL) workflows. FugueSQL’s additional keywords push down to the specified backend. For example,LOADwith the Spark engine using parquet will translate to PySpark’sspark.read.parquet.- Variable assignment reduces a lot of boilerplate code. Another change is the lack of an explicit
FROMclause. If there is noFROMclause, the DataFrame in the previous step is consumed automatically. - The
PERSISTkeyword pushes down to the backend persist (Spark in this case). This explicitly eliminates the recomputation of z just by adding one keyword.
The code snippet above was written in a Jupyter notebook cell. The query can easily be broken up into multiple cells (with some slight modification) compared to the original query. All we need to do is use the YIELD keyword to keep the DataFrame in memory (or file for bigger dataframes). This is a lot more natural for SQL users as they don’t need to deal with Python code to manage DataFrames in memory.
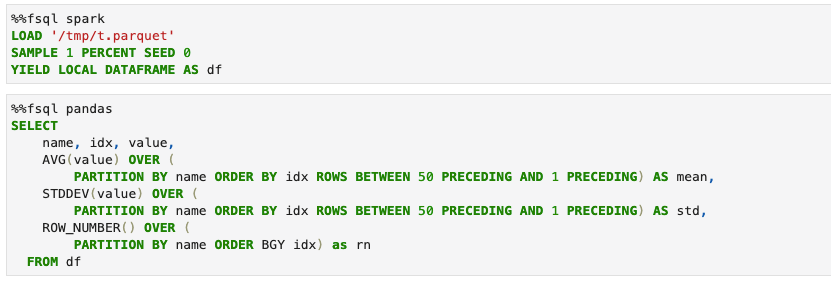
The important piece in this image is that we can iterate on sampled data using the Pandas or DuckDB engines before running the full thing on Spark. df is held in memory as a Pandas DataFrame because of the YIELD LOCAL DATAFRAME statement.
Though not covered in this article, FugueSQL is capable of interacting with Python code as well. Invoking Python functions from FugueSQL will be covered in a later article, but an example can be found here.
Conclusion
Sticking to traditional SQL makes it unable to express end-to-end compute workflows, often requiring supplementary Python code. Developer iteration time is slow because queries on big data can take a while, and running standard SQL requires all of the intermediate steps to be re-run. FugueSQL elevates SQL to be a first-class grammar and allows users to invoke Python code related to distributed systems with keywords such as **LOAD, SAVE, PERSIST**.
FugueSQL accelerates big data iteration speed by:
- Allowing seamless swapping of local and distributed backends (DuckDB or Pandas to Spark or Dask).
- Removing boilerplate code that standard SQL introduces.
- Adding keywords that invoke Python code, allowing SQL to serve as the predominant language as opposed to Python.
These enhancements allow SQL-lovers and data practitioners less fluent in Python to define their code in their preferred grammar. SQL’s strength is that it’s easily readable, and FugueSQL aims to extend this while keeping the intuitive and expressive spirit of standard SQL.